




Ruby support in key EPUB and Web layout engines remains inadequate for proper support of Japanese despite development of the appropriate standards at W3C. We suggest that key actors of the Japanese publishing industry reach out to their contacts at Apple and Google about this issue and also put forward and sign a public statement aimed at making the Web platform community aware of the interest in ruby being supported properly. We hope that this will motivate layout engines developers (particularly Google and Apple) to work on supporting this feature, encourage the latest HTML standard to be updated, and most importantly, to make it so that the ruby can finally be used reliably across the Web and in EPUB.
To make ruby work in e-books and on the Web, two technologies are needed: HTML to describe the content, the annotation, and their relationship; and CSS to specify the details of the layout.
If this is set up properly, we can achieve very flexible results: documents with ruby that are fully reflowable, with ruby annotations looking correct both in the middle of the line, and if there is a line break in the middle. We can also achieve personalizable content, when the readers can choose based on their preferences, disabilities, and reading proficiencies, if they want to annotate all characters or only some, and what kind of ruby layout they want, all from a single file, without any need to prepare different books for different people. This is useful for general readers, people with special needs, and school children…
The Japanese publishing industry, the Japanese Government, and various individual experts, have helped tremendously over the years in understanding the needs and supporting the writing of specifications.
While CSS standardization has been making good progress, the group responsible for the HTML specification is reluctant to accept the improvements developed with the W3C community, because not enough browsers vendors have expressed strong support. So far, the technology we're advocating for is largely supported in Firefox, and partly supported in Amazon Kindle. Google Chrome and Apple Safari/iBooks are behind, and only support an insufficient legacy ruby model. Since dedicated EPUB readers are often based on these engines, this problem limits what can be done for ebooks. In order to let the browser vendors know that this should be a higher priority, we would like to encourage publishing companies to express public support for this particular technologies.
Here is a suggestion for a possible text to that effect:
Correct ruby layout is intrinsic and important to Japanese text layout. It is found in almost all publications targeted at children and teenagers, and in a significant amount of publications aimed at adults as well. Furthermore, ruby is an accessibility feature, and its markup needs to support those needs as well as rendering correctly.
Ruby as implemented in Blink and WebKit today does not support Japanese properly. Our publishing industry finds it inadequate. It enables a limited subset of the expected functionality, but does not support correctly-formatted reflowable content and responsive design, nor allows varying presentations tailored to users with different needs. Searching, copy-paste, and other operations also don't work sensibly.
For proper support of Japanese, we would need the following to be implemented:
- Ability to mark up and render annotated compound (jukugo) words with correct space distribution, line-breaking, and inlining.
- Ability to vary the presentation of the document to accommodate different reading levels by showing some or all annotations, or by replacing some base characters with their annotations.
- Ability to distinguish between phonetic ruby and semantic ruby, particularly so that speech synthesis engines can know whether to pronounce both the base and the annotation or the annotation only.
The model followed by Firefox and Kindle, and specified by the CSSWG and former HTMLWG, shows how ruby can be marked up and rendered correctly. However, it has been many years that this is still not working correctly for Japan: it is not implemented in other engines, and is no longer included in the HTML standard. This is frustrating to the Japanese community, and undermines good-faith participation in worldwide consensus standards.
We request that the rest of the Web platform, its specifications, and rendering engines used for the web and for EPUB follow their lead so that electronic Japanese publications can finally be represented correctly in HTML+CSS.
The examples below can be attached as well in order to show clearly what our problems and expectations are.
Here are some examples illustrating the problems and limitations of the legacy implementations and the desired behavior and rendering of Japanese ruby.
Ruby layout over a compound word (jukugo) can be laid out in different styles.
Line breaking of compound words needs to be allowed and to preserve the correct pairing between base characters and their annotations.
Correct pairing between base characters and their annotation
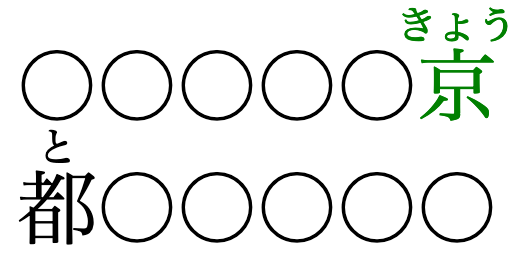
Incorrect pairing
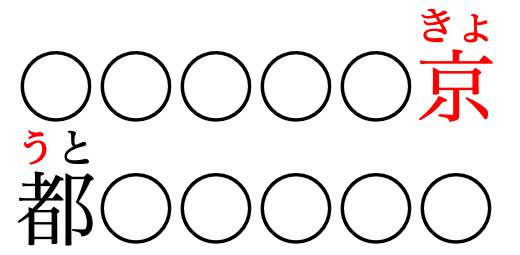
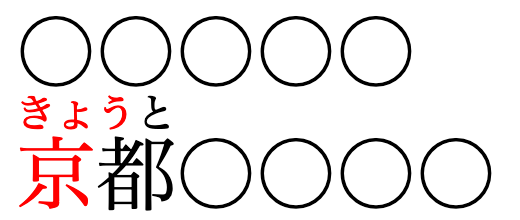
Line breaking prevented inside words
This requires that the markup both expresses the paring between each base and its annotation, as well as groups them by word.
The underlying structure of the ruby markup also matters.
The markup pattern supported by Blink and WebKit could be used to present compound words
if the layout model was changed;
but even in that case,
because it breaks the compound word into pieces
interleaved with the annotation,
inlined presentation,
search,
copy-paste,
and speech synthesis work poorly.

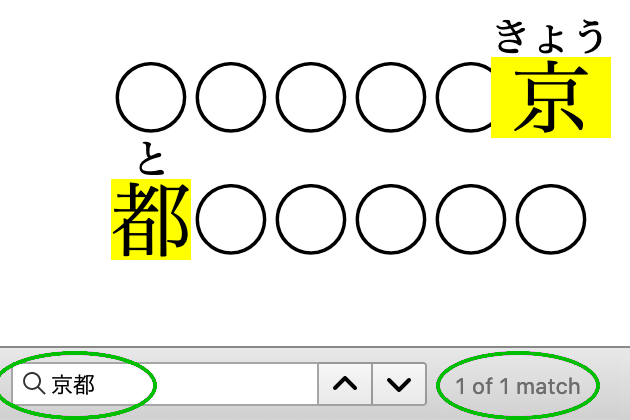


Japanese books and educational materials need to support variations
appropriate for different ages, school grades, reading preferences, and disabilities.
It should be possible to produce all of these variations from a single source.
“mono” ruby (individual space) presentation
Clear correspondance between annotation and base,
but introduces unnecessary space in the base text
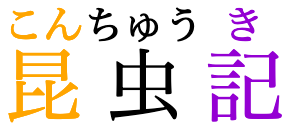
“jukugo” ruby (shared space) presentation
Muddles correspondance between annotations and base characters,
but avoids unnecessary space in the base text

hiding phonetic annotations for “easy” kanji
Hiding annotations kept available in the markup
allows for pedagogical choice in educational material and for accommodating reader preference (for example, some people with dyslexia find ruby distracting and prefer to hide it where non-essential).

hiding phonetic annotations for all common kanji

replacing kanji (base text) with kana (annotations)
Kana-only texts can be more comfortable for readers who can't read kanji.
providing annotation as full-sized parenthesized text
Fallback rendering for engines without support for ruby, but can also be used as a deliberate choice for readability at small font sizes or to avoid needing large inter-line gaps.


mixed-mode presentation
Inlined phonetics for hard kanji, hidden annotation for easy kanji, phonetic ruby for at-level kanji.

Inlined phonetics for hard kanji, hidden annotation for easy kanji.


Although less commonly used,
double-sided ruby exists,
and should eventually be addressed also.
A typical use case would be
to provide a familiar loanword
alongside a native but somewhat obscure or ambiguous Japanese word
that also needs to be annotated for pronunciation.
