




日本語書籍を適切に表現するにはルビをきちんとサポートする必要があります。しかし、主要なEPUBやWebレイアウトエンジンにおけるルビの実装は、残念ながら不十分です。W3Cで適切な標準が策定されるよう努力してきましたが、実装を変えるまでには至っていません。
現状を改善するために、日本の出版界に二つのアクションをお願いしたいと思います。一つは、この問題についてAppleやGoogleの関係者に働きかけることです。もう一つは、公的な声明を発表し、ルビの正しい実装に関心があるとWebプラットフォーム・コミュニティに認識してもらうことです。
これらのアクションを取っていただくことにより、レイアウトエンジンの開発者 (特にGoogleとApple) がこの機能のサポートに取り組み、最新のHTML規格 (WHATWG) の更新を促し、最終的にウェブ全体とEPUBでルビがどこでも同じように安心して使えるようになることを期待しております。
電子書籍やWebでルビを使うためには、HTMLとCSSという2つの技術が必要です。 HTMLは、コンテンツ、アノテーション、およびそれらの関係を記述します。 CSSは、組版の詳細を指定します。
これらが適切に設定されていれば、非常に柔軟な結果を得ることができます。例えば、ルビ付きの文書は完全にリフロー可能になりますし、ルビは一行に収まるときも複数の行にまたがるときも正しく表示されます。バリアフリーな読書のために、読み手の好み、障害の有無、読みの習熟度に応じて、ルビの表示を変更できます。総ルビ表示にするのかパラルビ表示にするのか、レイアウトの調整(例えばルビの大きさや色の変更、親文字との距離の調整)をするのかを、同一のファイルのままで切り替えることができ、人によって異なるファイルを用意する必要がありません。これは、一般の読者はもちろん、障害者や学校の子供たちにも便利です。
日本の出版業界、日本政府、そして様々な専門家の方々が、長年にわたってニーズを把握し、仕様書の作成をサポートしてくださっています。
CSSの標準化は順調に進んでいますが、HTMLの仕様を担当するグループは、十分な数のブラウザベンダーが強い支持を表明していないため、W3Cコミュニティで開発された改良点を受け入れようとしません。今のところ、私たちが提唱している技術は、Firefoxでは大部分がサポートされており、Amazon Kindleではある程度サポートされています。Google ChromeやApple Safari/iBooksは遅れていて、不十分な既存のルビモデルをサポートしているだけです。専用のEPUBリーダーはこれらのエンジンをベースにしていることが多いので、この問題は電子書籍にできることを制限してしまいます。ブラウザベンダーにこの問題の優先順位が高いことを知らせるため、出版社にこの特定の技術への支持を表明して頂ければと考えています。
そのような趣旨の文章の案を示します。
正しいルビのレイアウトは、日本語の文章レイアウトにとって本質的で重要なものです。ルビは、子供やティーンエイジャーを対象としたほとんどすべての出版物に見られ、大人を対象とした出版物にもかなりの割合で見られます。さらに、ルビはアクセシビリティのための機能です。ルビのマークアップは、正しい表示だけでなく、アクセシビリティについてのユーザ要求をサポートする必要があります。
現在、BlinkやWebKitに実装されているルビは、日本語を適切にサポートしているとは言えません。私たち出版業界は、それを不適切だと感じています。期待される機能のうちの一部は実現していますが、正しくフォーマットされたリフロー可能なコンテンツやレスポンシブデザインには対応していませんし、異なるニーズを持つユーザーに合わせてさまざまな表示を行うこともできません。また、検索やコピー&ペーストなどの操作もきちんと行うことができません。
日本語に対応するためには、以下のような機能が必要です。
-
熟語ルビをマークアップで表現し、表示できること。親文字の字間とルビの字間とを適切に調整すること。行末にあるなら適切な位置で二行に分け、行中にあるなら一つの行に収めること。
-
読み手のレベルに合わせてドキュメントの表示を変えられること。具体的には、総ルビ表示とパラルビ表示を使いわける、親文字をルビで置き換えるなど。
-
発音を表すルビ(フリガナ)とそれ以外(義訓など)のルビを区別できるようにすること。これによって、親文字とルビの両方を読み上げるべきなのか、ルビだけを読み上げるべきなのかを音声合成エンジンが区別できるようになります。
FirefoxやKindleで採用され、W3CのCSS WGや旧HTML WGで規定されているモデルは、ルビの適切なマークアップと表示を可能にしています。しかし、他のエンジンでは実装されておらず、HTML標準にも含まれていません。FirefoxやKindleで(仕様通り)動作するものが、他のエンジンでは動作しないという状態が続いています。日本のコミュニティはこの現状に不満を感じています。また、現状は、世界的な合意に基づいて標準化を行うという基本方針への疑念を抱かせるものです。
私たちは、前述したモデルを他のウェブプラットフォームが採用することを要請します。仕様もこのモデルを採用すべきですし、ウェブやEPUBに使用されるレンダリングエンジンもこのモデルを実装すべきだと思います。そうすれば、日本の電子出版物がついにHTML+CSSで正しく表現できるようになります。
英語版:
Correct ruby layout is intrinsic and important to Japanese text layout.
It is found in almost all publications targeted at children and teenagers,
and in a significant amount of publications aimed at adults as well.
Furthermore, ruby is an accessibility feature,
and its markup needs to support those needs as well as rendering correctly.
Ruby as implemented in Blink and WebKit today does not support Japanese properly.
Our publishing industry finds it inadequate.
It enables a limited subset of the expected functionality,
but does not support correctly-formatted reflowable content and responsive design,
nor allows varying presentations tailored to users with different needs.
Searching, copy-paste, and other operations also don't work sensibly.
For proper support of Japanese, we would need the following to be implemented:
-
Ability to mark up and render annotated compound (jukugo) words
with correct space distribution, line-breaking, and inlining.
-
Ability to vary the presentation of the document
to accommodate different reading levels by showing some or all annotations,
or by replacing some base characters with their annotations.
-
Ability to distinguish between phonetic ruby and semantic ruby,
particularly so that speech synthesis engines can know
whether to pronounce both the base and the annotation
or the annotation only.
The model followed by Firefox and Kindle,
and specified by the CSSWG and former HTMLWG,
shows how ruby can be marked up and rendered correctly.
However, it has been many years that this is still not working correctly for Japan:
it is not implemented in other engines,
and is no longer included in the HTML standard.
This is frustrating to the Japanese community,
and undermines good-faith participation in worldwide consensus standards.
We request that the rest of the Web platform,
its specifications,
and rendering engines used for the web and for EPUB
follow their lead so that electronic Japanese publications can finally be represented correctly in HTML+CSS.
以下の事例を添付すれば、われわれが何を問題視していて、何を期待しているのかを明確にできると思います。
ここで示す例は、従来実装の問題点や限界を明らかにし、日本語ルビの望ましい動作や表示を提示します。
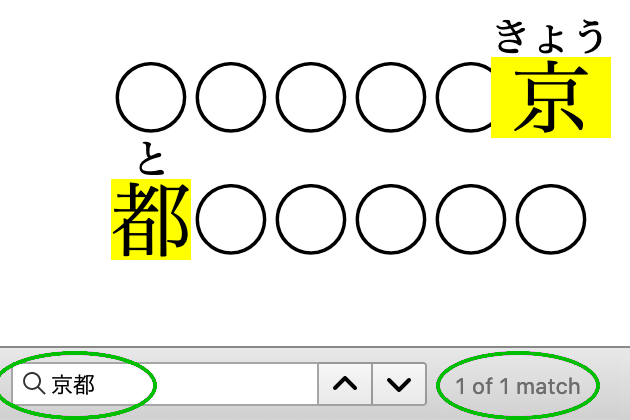
熟語に対するルビのレイアウトには、様々なスタイルがあります。
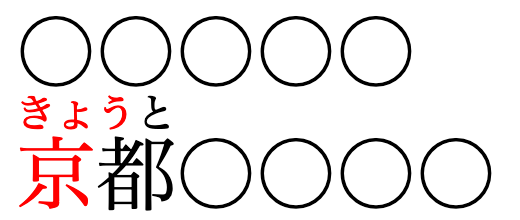
熟語の途中での改行を許し、親文字とそれに付されたルビの正しい対応を維持する必要があります。
親文字とそのルビの正しい対応
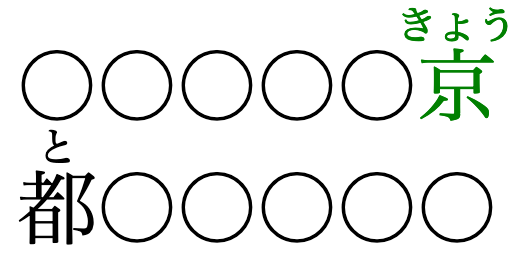
正しくない対応
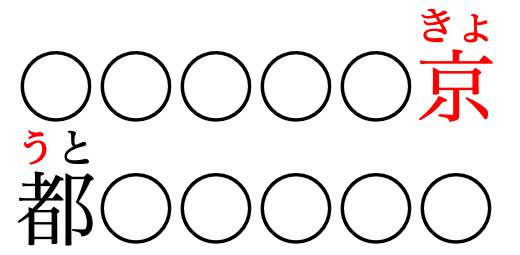
熟語内での改行を行えないという欠陥
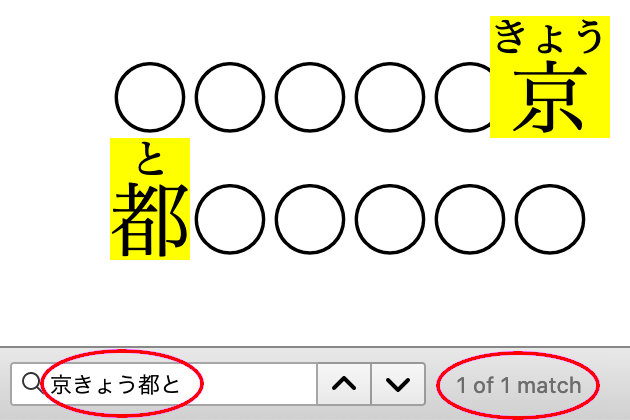
上記のことを可能にするには、マークアップには二つの要求を満たす必要があります。第一に、どの親文字にどのルビが対応するかを表現する必要があります。第二に、熟語全体としてのグループ化を表現する必要があります。
ルビのマークアップの基本構造も重要です。BlinkやWebKitでサポートされているマークアップは、レイアウトモデルを変更すれば熟語ルビのレイアウトにも使用できます。しかし、その場合でも、熟語の途中にルビが現れてしまうため、パーレンを用いた表示、検索、コピー&ペースト、音声合成などがうまくいきません。



日本語の書籍や教材は、年齢・学年・読書の好み・障害の有無などに応じて、ルビの表示を工夫すると読みやすくなります。表示のとき、別のHTMLファイルを用いることなしに、こうした切替ができることが求められます。
モノルビ(親文字ごとに別のルビ領域がある)表示
ルビと親文字の対応は明確だが、親文字の字間が間延びすることがあります。
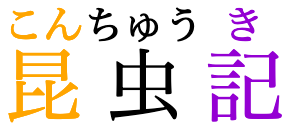
熟語ルビ(熟語全体でルビ領域を共有する)表示
ルビと親文字の対応関係はやや曖昧になるが、親文字の字間が間延びすることはありません。

簡単な漢字のルビは隠す
マークアップでは利用可能にしておいたルビを隠すことで、教材を習熟度や読者の好みに合わせることができます(例えば、ディスレクシアの人の中には、ルビが邪魔だと感じ、必要のないところではルビを隠しておきたいと思う人もいます)。

普通の漢字すべてのルビを隠す

親文字(漢字)をルビ(仮名)に置き換える
仮名だけのテキストは、漢字を読めない読者にとってより快適なものになります。
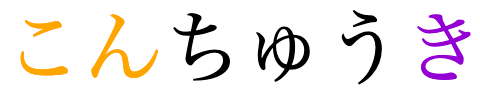
注釈をパーレン付きテキストで表示する
ルビに対応していないエンジンのためのフォールバック表示ですが、小さなフォントサイズでの読みやすさや、広くない行間に対応するために、意図的に使用することもできます。


混合モード表示
難しい漢字は仮名で置き換え、簡単な漢字はルビを隠し、レベルの高い漢字にはルビを表示します。

難しい漢字は仮名で置き換え、簡単な漢字にはルビを隠しています。


あまり一般的ではありませんが、両面ルビも存在しており、いずれは対応する必要があります。
